The Case for Learned Index Structures
Paper review; publication year: 2017
The Google-brewed paper has thought-provoking ideas and is poised to be remembered for a long time.
The paper’s key question is: can indexing data structures (e.g. B-Trees or HashMaps) be replaced with machine learning models (e.g. Neural Networks) ? (Figure 1).
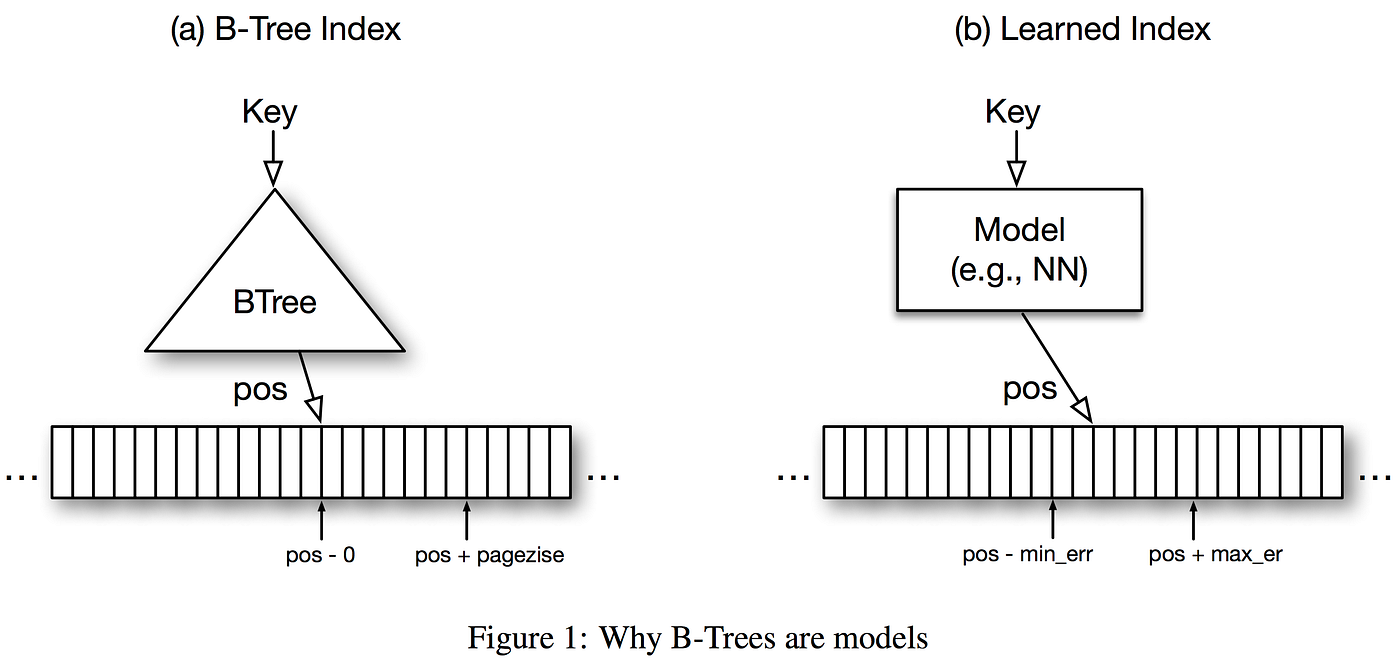
This simple question completely broke mine and others’ previous idea of what an index is:
Before: indexes == data structures
Now: indexes == modelsBefore I just had the vague idea that indexes were clever data structures and algorithms. However, more abstractly, indexes can be seen as models: f(key) == pos. That is, given a key, return a (pos)ition as modeled by f. Like so, f can indeed be a data structure/algorithm, but more generally any function, and specifically a machine learning model too. Ergo, we can potentially machine-learn how to efficiently index data so as to (1) speed up look ups or insertions, and (2) consume low memory.
Structures like B-Trees, HashMaps, or Bloom Filters, give strong guarantees of error margins and computational complexity. A priori, it would seem impossible for machine learning (ML) models to offer the same guarantees. The authors achieve in this paper to show exactly that: ML models can have similar or even better guarantees. Not only that, but also ML models could even be more efficient (for (1) speed and (2) memory). Why? B-Trees and the like are general-purpose data structures. Comparably, ML models can potentially learn from and exploit specific patterns in (real-world) data.
After posing the main question, the authors demonstrate that traditional data structures can indeed be replaced by (ML-)learned indexes by showcasing their in-house ML implementations in three different types of indexes: 1) A range index (i.e. given a key, return a range of sorted positions), 2) a point index (i.e. given a key, return a single unsorted position), and 3) an existence index (i.e., given a key, return whether it exists or not). As per the main question, the range and point indexes can be seen as regression models, and the existence index as a classification task.
The authors then benchmarked their ML implementations. Long story short, their learned indexes showed: 1) vs. B-Trees for range indexes: up to 70% faster look up and close to 100% (yes) less memory; 2) vs. HashMaps for point indexes: slightly slower access times traded for up to 20% less memory; and 3) vs. Bloom Filters for existence indexes: up to 40% less memory.
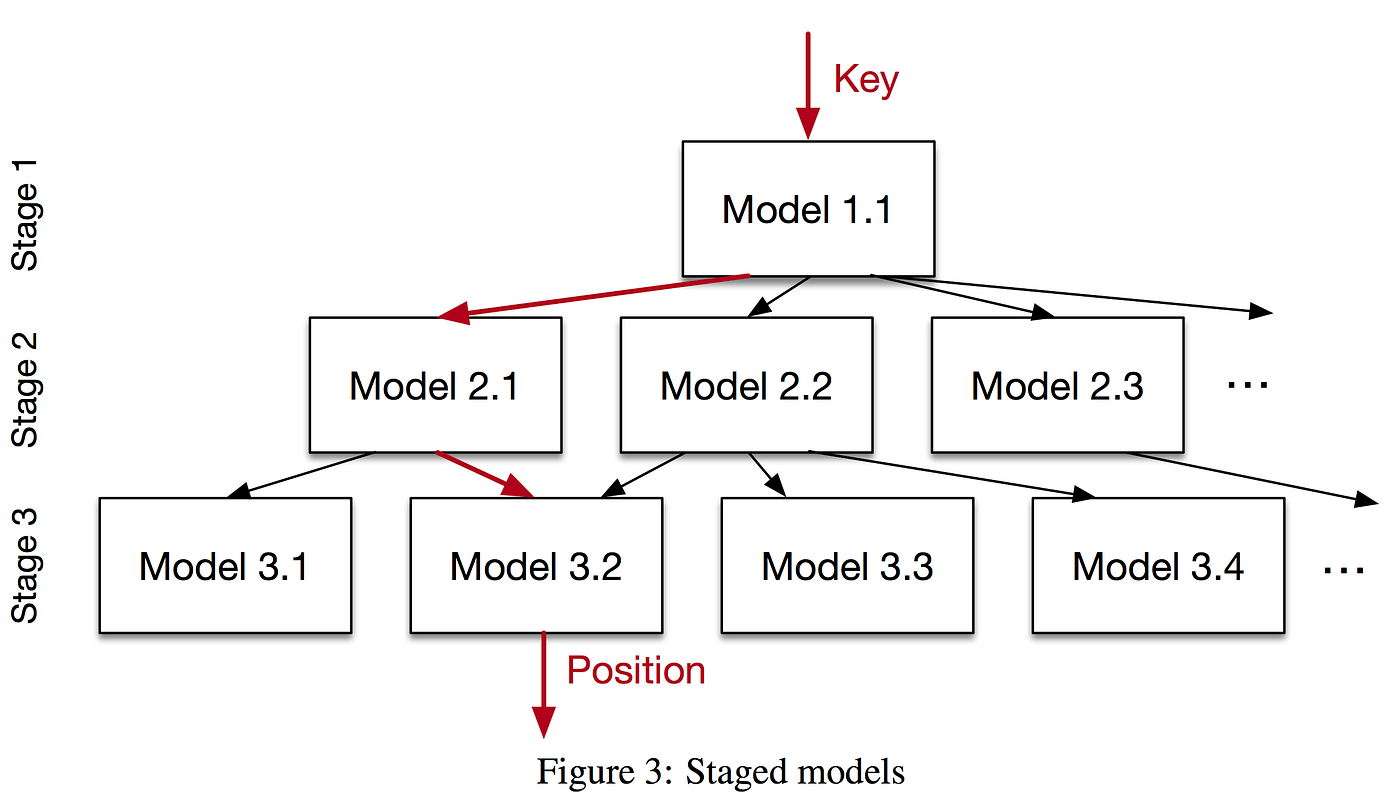
The second greatest contribution of the paper is the practical implementation of a learned range index (i.e. vs B-Trees) as a mixture of experts. They called it: the recursive-model index (RMI) (Figure 3). The authors showed in a practical setting the benefits of such a layered and hierarchical system. For example, used to model a cumulative distribution function (CDF) for a range index, the upper layers can approximate better the general shape of the CDF, whereas the leaf models can solve and focus on the last mile, that is the last data instances where the distribution is not any more smooth (i.e. shows more randomness). In particular, the leaf nodes could be implemented with traditional data structures like B-Trees (in contrast to e.g. neural networks), in case the machine learning models could not generalize the data or showed worse performance. The authors called this combination of different traditional and machine models hybrid indexes.
Future
- The scope of the work was on index lookups (reads), and not insertions. The authors indeed provided many suggestions for how insertions could be solved and have a positive outlook on this task. Further research on insertions for learned indexes should be next.
- An exciting potential for learned indexes is to learn multi-dimensional index structures. That is, this opens the possibility of efficiently searching for and ranking data structures that contain many data points.
- Learned algorithms: the authors hint that the main idea of learning indexes could well be expanded over more general algorithms, such as data joining or sorting.
- Improvements with GPUs/TPUs: the authors hit the spot by pointing out that branching parallel properties of learned indexes could be implemented with and thus benefit from the exponential gains expected for GPUs and TPUs (in contrast to Moore’s law for CPUs which is essentially dead).
- The many positive answers and improvements could well signify that databases development (and many other programming tasks) could be taken over by AI. Compare with the recent work of turning design mock ups into real html code using neural networks.
- I am looking forward to seeing the first open source real database implementations that use learned indexes.
The Good
- Despite the many innovative ideas, the paper is exquisitely easy to read.
- The authors discussed several practical details, including considering how disk paging could affect the performance of database learned indexes.
- The authors left many inspiring open questions and even included hypothetical solutions.
To improve
- The authors did not provide direct links to the datasets used, nor code for their machine learning implementations. Reproducibility is futile.
Links & References
- The original paper.
- Paper inspiration for the mixture of experts: Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
- Paper discussion on Hacker News.
- Critics to the paper and stimulating discussion with the original authors (thank you Kordian Bruck!)
At 🍃tagtog.net we aim to make text analytics trivial to use for everybody.
👏👏👏 if you liked the post and want to share it with others!
